Overview id-mask bkdf singlestep-kdf bcrypt slf4j-timber armadillo bytes-java hkdf dice under-the-hood uber-apk-signer uber-adb-tools indoor-positioning density-converter Dali BlurTestAndroid
In this article I will show you how to strengthen ProGuard’s name obfuscation, making it harder for an attacker the reverse engineer your…
Android, Proguard, Security, AndroidDev, Android App Development
linkImproving ProGuard Name Obfuscation
Improving ProGuard Name Obfuscation
In this article I will show you how to strengthen ProGuard’s name obfuscation, making it harder for an attacker the reverse engineer your code and how this will help prevent many bugs created by incorrect obfuscation
I‘ll tell you a secret: ProGuard is actually a code optimizer. One of the optimization’s side-effects just happen to add some name obfuscation to the resulting byte code, namely the shorting and reusing of class and method-names. The actually benefit being, that the resulting binary is smaller and better compressible (smaller binaries can be loaded faster into the heap, ie. reduce latency).
linkHow does ProGuard’s Name Obfuscation work
ProGuard uses dictionaries to define to what to rename a package, class or method. There is a default dictionary which just contains the letters a-z.
Let’s consider the following code with this lonely class:
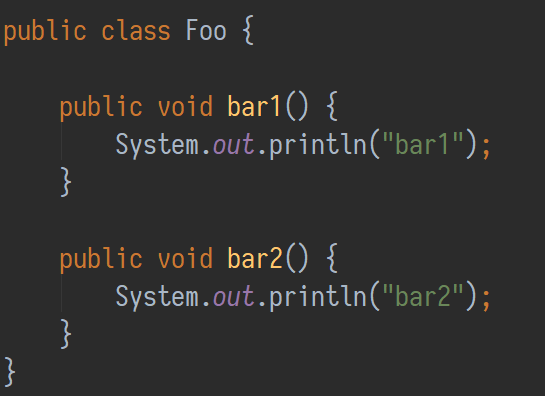
When optimizing with ProGuard, it will start by processing Foo.class. ProGuard will check it’s dictionary, the first entry being the letter a. There is no class with that name in this package, so this will result in Foo.class being renamed to a.class. Next the methods will be renamed: bar1() will turn into a() and bar2() into b() using the same strategy. A Java syntax representation of the resulting class would look like this:
 Obfuscated version of class Foo
Obfuscated version of class Foo
Now if you would add a new class Foobar.class it would be renamed to b.class and so on. If there are more then 26 classes in a package, the name gets longer: aa.class, ab.class, etc.
linkPreventing Deterministic Name Obfuscation
The name obfuscation** process is deterministic**. There is a defined ordering (I guess it is just lexicographical) in which the class are processed, so Foo.class would still be a.class and the methods would still be a() and b() respectively after adding a second class. That does not mean it will never change. If a class is added, which ordered, is in the middle of other classes the obfuscation mapping_ will_ change, but often than not the mapping stays similar over builds.
From a security standpoint this is not optimal. If an attacker knows that in version 1 of your app a.b() is e.g. your licence check logic, it will be easy to find that same logic in version 2 if it is still a.b().
linkProviding Custom Name Obfuscation Dictionary
ProGuard allows you to define the following dictionaries: (see the official manual for more info)
1**-obfuscationdictionary** method-dictionary.txt** -packageobfuscationdictionary** package-dictionary.txt** -classobfuscationdictionary** class-dictionary.txt
The format of which are just a simple text file with an entry each line, ignoring empty lines and lines starting with #
1# A custom method dictonary
2
3NUL
4CoM4
5COm9
6lpt2
7com5
It is possible to have a little fun with these files. For instance, in the ProGuard distribution, there are some examples of alternative dictionaries. This file contains names which will make it impossible to extract the classes from the package (e.g .jar) in Windows because it would create illegal file names. Another version is optimized to enable the best possible compression by using common small keywords in the byte code format. Another option is to use Java keywords as class and method names which is allowed in the byte code format creating very confusing stack traces.
Either way, this somewhat improves name obfuscation, but we still have the problem of it being fully deterministic.
linkRandomizing the Dictionary
Eric Lafortune, the creator of ProGuard (and it’s commercial counter-part DexGuard) intended the obfuscation to be deterministic (see this features request about randomization of the dictionary) but there is an easy trick to work around that: In our build tool, before executing ProGuard, we just generate a file with a random dictionary.
Using the Android Gradle build process as example, you could dynamically add a task which runs before ProGuard task itself:
1tasks.whenTaskAdded { currentTask ->
2 //Android Gradle plugin may change this task name in the future
3 def prefix = 'transformClassesAndResourcesWithProguardFor'
4
5 if (currentTask.name.startsWith(prefix)) {
6
7 def taskName = currentTask.name.replace(prefix,
8 'createProguardDictionariesFor')
9
10 task "$taskName" {
11 doLast {
12 createRandomizedDictonaries()
13 }
14 }
15
16 //append scramble task to proguard task
17 currentTask.dependsOn "$taskName"
18 }
19}
Now in the task you would need to do the following:
Read a template file with all possible dictionary entries
Shuffle the entries; do not pick 100% of the entries but a random amount between e.g. 60–90% so mappings cannot be easily converted between builds
Write the entries to a file
Reference the file in your ProGuard with
-obfuscationdictionaryRepeat the steps for the class dictionary
-classobfuscationdictionary
linkAdditional Features
Another feature I would suggest is the option to repackage all classes to a single package. This config would move all classes to a root-level package o
1**-repackageclasses** 'o'
This can also be set dynamically with a similar logic described as above.
For easier debugging you can print out the assembled ProGuard config (when using multiple config files) with
1**-printconfiguration** proguard-merge-config.txt
linkConsequence of using Random Name Obfuscation
Be aware that each build variation_ will have a practically unique obfuscation mapping_. So in an Android build, each build variant (flavor or build type) will create very different stack traces. So be careful to_ keep all the mappings_ for every version, flavor and build-type in Gradle and all classifiers in Maven.
This isn’t a disadvantage though. One bug which many Android developers experience at least once:_ persisting of obfuscated names which makes migration impossible_. This usually happens when a Json databinding serializer is used, which reads class and method names through reflection and converts them, or by using *.getClass().getName() is used with either SharedPreferences or Databases. The worst part is: this usually doesn’t get noticed because the name obfuscation mapping could stay the same for next couple of releases. So you are stuck with e.g.
1{
2 "xf": {
3 "a": "Foo",
4 "ce": {
5 "tx": [{
6 "by": "Foobar",
7 "bv": 137
8 }]
9 }
10 }
11}
By forcing a different mapping each build, bugs like these will immediately surface, essentially_ creating a fail-fast for ProGuard mappings_.
linkSummary
ProGuard’s name obfuscation is_ deterministic_, therefore when the code only changes a little the_ mappings mostly stay the same_ over multiple releases
It is possible create_ randomized dictionary_ for the obfuscation and tell ProGuard to use them, so every build will have a_ unique mapping_, making it harder for an attacker to reverse engineer your code
Randomized name obfuscation also has the advantage of_ acting as a fail-fast_ so common ProGuard configuration issues will
This article was published on 2/1/2020 on medium.com.